Mennyit Késik?
Introduction
A year ago, I posted an article about the collection of railway traffic data in Hungary, and now it is time to develop a machine learning model and an application based on the gathered data.
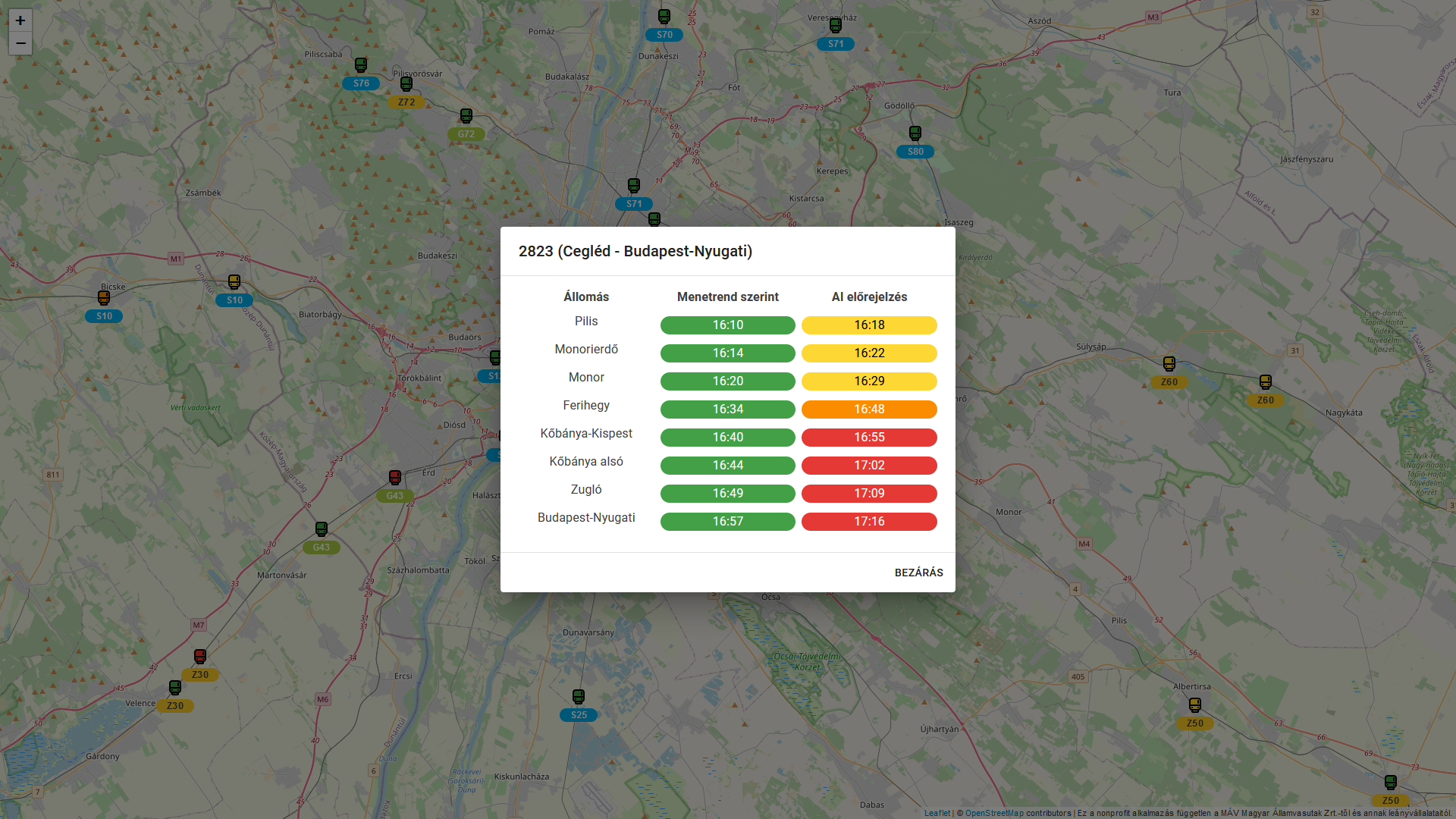
The name of the solution is Mennyit Késik?, which translates to “How late it is?” in English. It is capable of predicting delays up to 60 minutes in advance for each suburban train and the predictions are displayed in an interactive map.
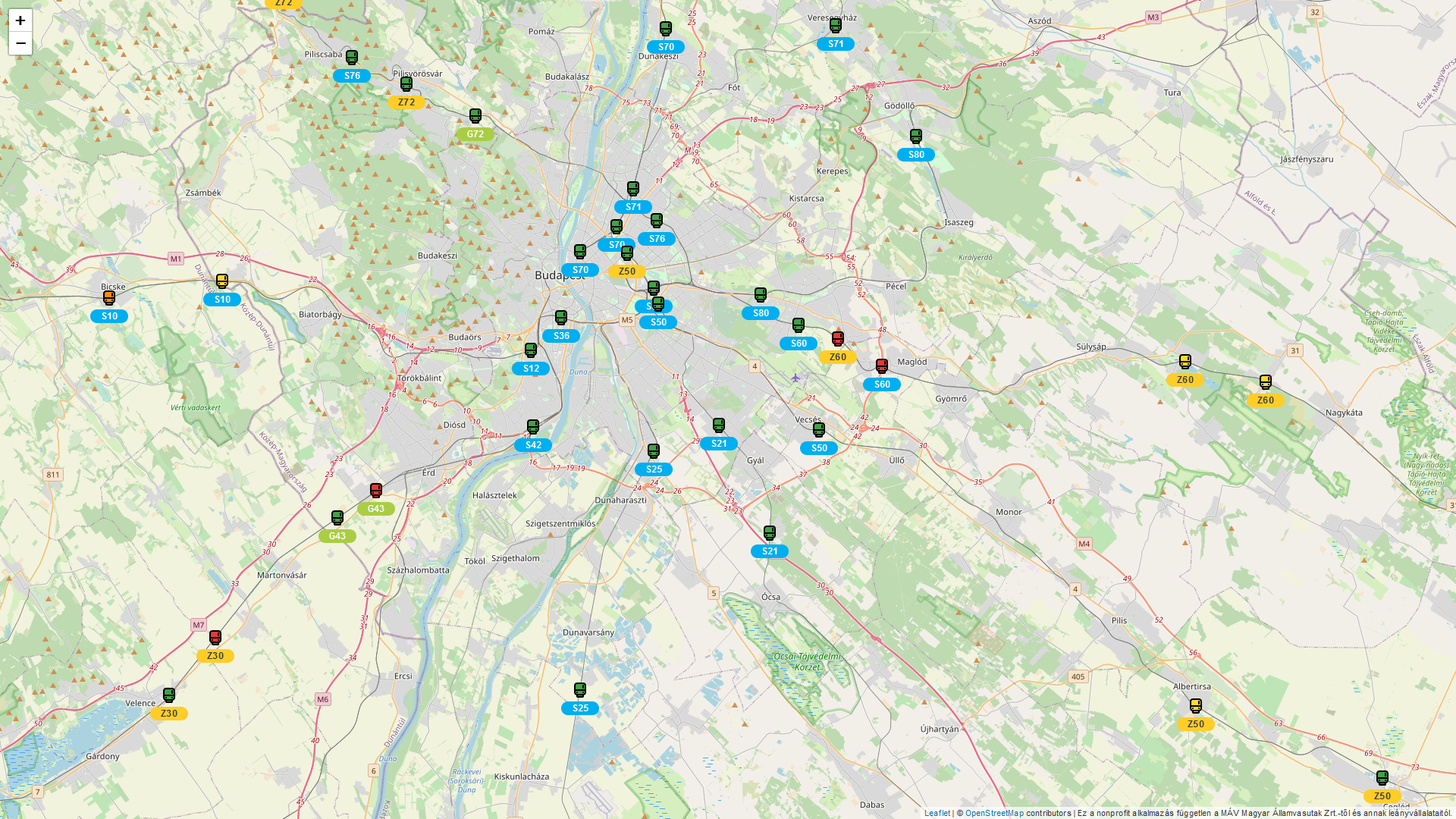
Architecture
The solution consists of the following main building blocks:
- Data collection
- Data storage
- Data processing
- Hyperparameter optimization and model training
- Model execution
- Application backend
- Application frontend
Data collection
The first step is a collection of lambda functions integrated with multiple data sources. These functions run on a fixed-size VPS, as it does not need to scale. The details of the data collection can be found in a previous article.
Data storage
On the same VPS there is a MinIO instance running, which is an S3 compatible object storage. The collected data are stored in a MinIO bucket, and they are aggregated and compressed daily using a lambda function to save space.
Data processing
To create a maintainable data pipeline, I started the project with QuantumBlack Labs’ kedro framework. Kedro is an open-source Python framework for creating reproducible, maintainable, and modular data science code. It borrows concepts from software engineering and applies them to machine-learning code.
The pipeline starts by preprocessing the data available in the MinIO bucket, then proceeds to cleaning, feature extraction, and model input generation.
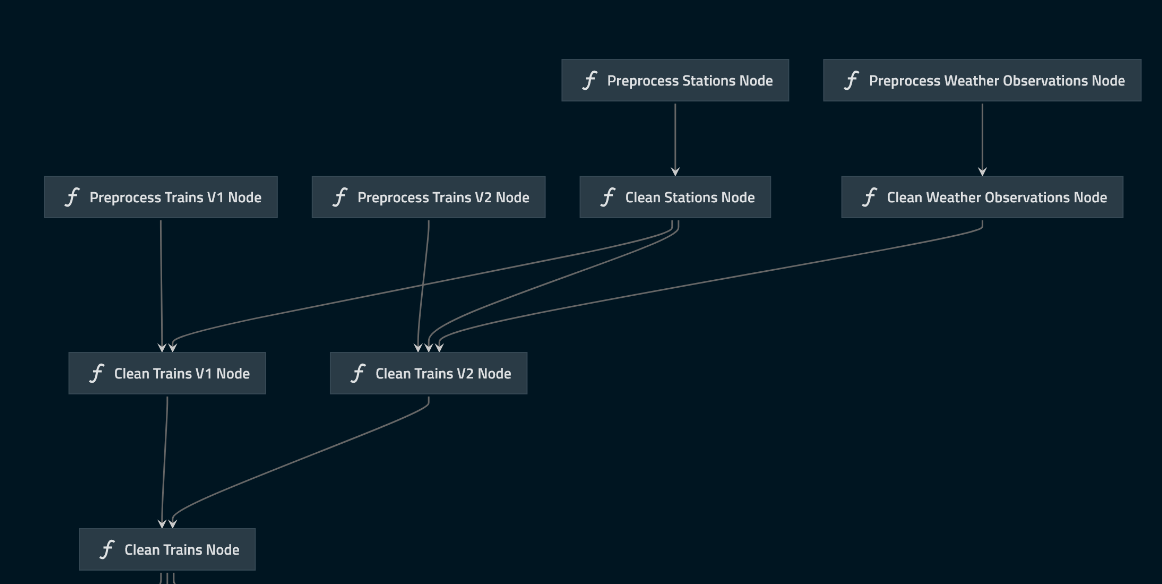
Hyperparameter optimization and model training
For each train, a distinct LightGBM model is trained. The input of the model consists of both auxiliary and time-series features. The hyperparameter optimization uses the hyperopt library, and the calculated hyperparameters are stored in a MinIO bucket, which can be reused for subsequent pipeline runs. By using the calculated hyperparameters, the models are trained with all available data and are stored in a MinIO bucket.
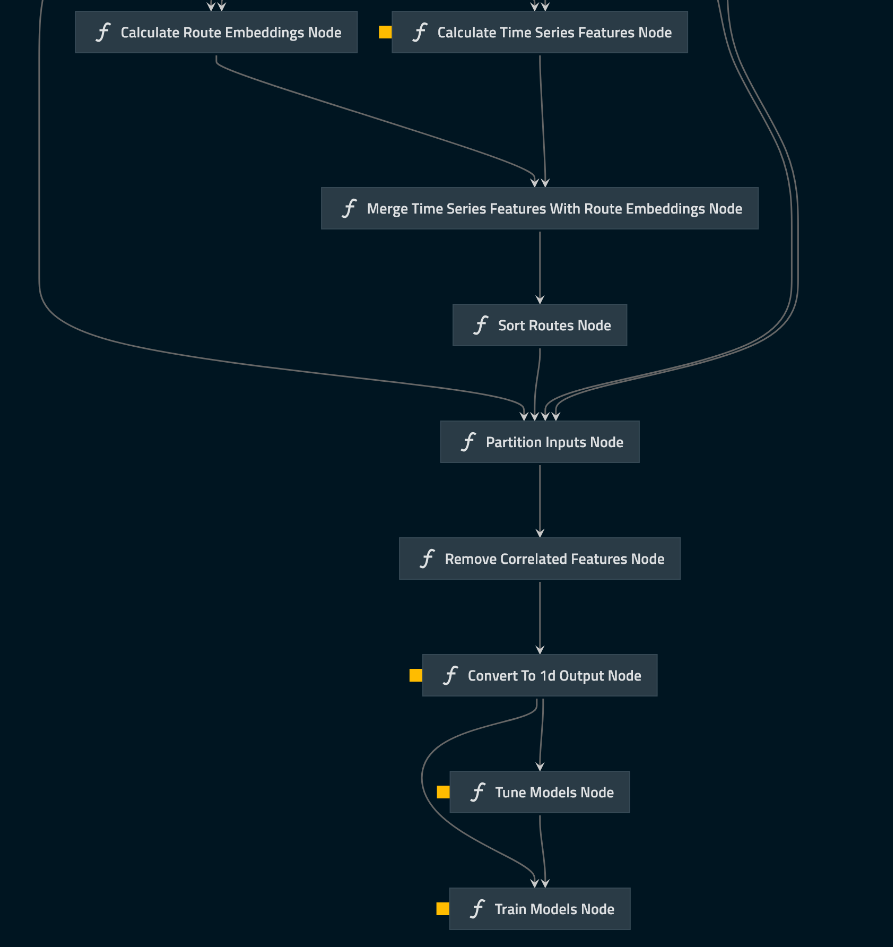
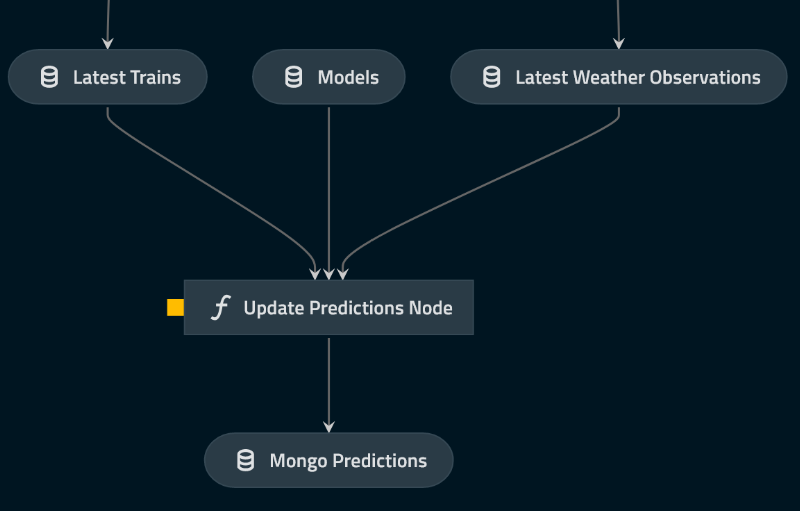
Model execution
The trained models are executed each time new data becomes available and the results are stored in a MongoDB database.
Application backend
The backend of the solution is a NestJS application running on Heroku, and its main purpose is to serve the predictions to the frontend as they are found in the MongoDB database. It is completely independent from the core application logic, and it can be scaled as the number of users increase.
Application frontend
The frontend of the solution is a simple Next.js application consisting of a map, which visualizes the predictions for the end-users.